

Every billing team knows the feeling. A claim comes back denied. Someone digs in, finds the problem: an authorization that lapsed, a patient name that didn't match, a payer quirk your team has seen a dozen times before. The issue was preventable. Nobody caught it.
Now multiply that by a thousand claims a month.
At NHIA 2026, SolisRx CEO Chris Hilger presented a session called Better Denial Management with Simple AI Models. The central argument was clear: most denials are predictable. And predictable problems, with the right data, become preventable ones.
The Real Problem Is Prioritization
Rising denial rates aren't just a billing problem. They're a prioritization problem. Your team can't scrutinize every outgoing claim. Nobody can. So claims go out the door, many get denied for entirely preventable reasons, and the cycle repeats.
The answer isn't hiring more billers. It's getting smarter about which claims actually need human attention before submission.
Chris reframed the challenge. It's not a denial problem, it's a prioritization problem. The goal isn't to review everything. It's to focus your team's attention on the 10% of claims most likely to drive 80% of your denial dollars, before submission.
A supervised machine learning model, trained on your own historical claims data, can do exactly that.
Don't Skip Steps to Get to AI

Before getting into the mechanics, Chris walked through what he calls the Data Sophistication Framework, or the "Mountain Slide": six levels of data maturity starting from a basic unified data source and climbing toward generative AI at the peak. Most infusion organizations are still at levels one or two, and jumping straight to AI platforms without the right data foundation is a recipe for disruptive, frustrating, and usually expensive failure.
The right target for most providers right now is get to level three (a Centralized Data Lake that enables a connected view of data across your EHR, billing system, CRM, and other platforms) at the earliest. That's the foundation that opens the door for more sophistication and makes the high-ROI data analytics possible.
Reaching level five (ML Classification Models) is extremely rewarding for most organizations. These aren't experimental tools. The same class of models has been running spam filters, predicting customer churn, and driving pricing engines for 15-plus years across industries. Proven, practical, and now accessible enough to bring into an infusion billing workflow.
At this point, infusion organization can begin meaningful GenAI Pilots, safely and successfully automating entire workflows, and achieving new levels of efficiency.
Dollars at Risk, Not Just Risk Scores
Chris walked through a live demo, showing the end-to-end workflow in enough detail that operators could realistically attempt a proof of concept on their own.
You start with 12 to 24 months of historical claims from your 835 files, combined with encounter data from your EHR. Each row is a claim. Each column is a feature: payer, drug, patient demographics, submission timing, prior authorization date, contract amount. The most important column: was this claim denied, yes or no?
That labeled historical dataset is what trains the model. It learns which combinations of features have historically predicted a denial. Once trained, you run new, pre-submission claims through it and get a risk score: a number between 0 and 100% representing the likelihood that claim gets denied.
But the risk score alone only tells part of the story. Multiply it by the estimated contract amount and you get dollars at risk. And that number changes everything about how your team prioritizes. A claim with a 30% denial probability on a $40,000 infusion drug outranks a 70% risk claim on a $500 charge every time. The demo showed this directly: the highest-priority claim by dollars at risk was sitting in eighth place on the raw risk score list.
Chris also covered feature engineering: the practice of creating derived columns that help the model learn faster. Three that matter most in infusion: historic denial rate by payer (Blue Cross vs. United, for example), denial history by patient, and denial rate by referring provider.
Most billing teams develop an excellent gut sense about these correlations, but the advantage of an ML model is that it confirms and quantifies their intuition, accurately and consistently.
For teams without data engineering resources, Chris pointed to Power Query inside Excel as a no-code starting point for the data prep work. Free, already licensed, and capable enough to handle deduplication of 835 remits and initial claim-level aggregation.
The Result
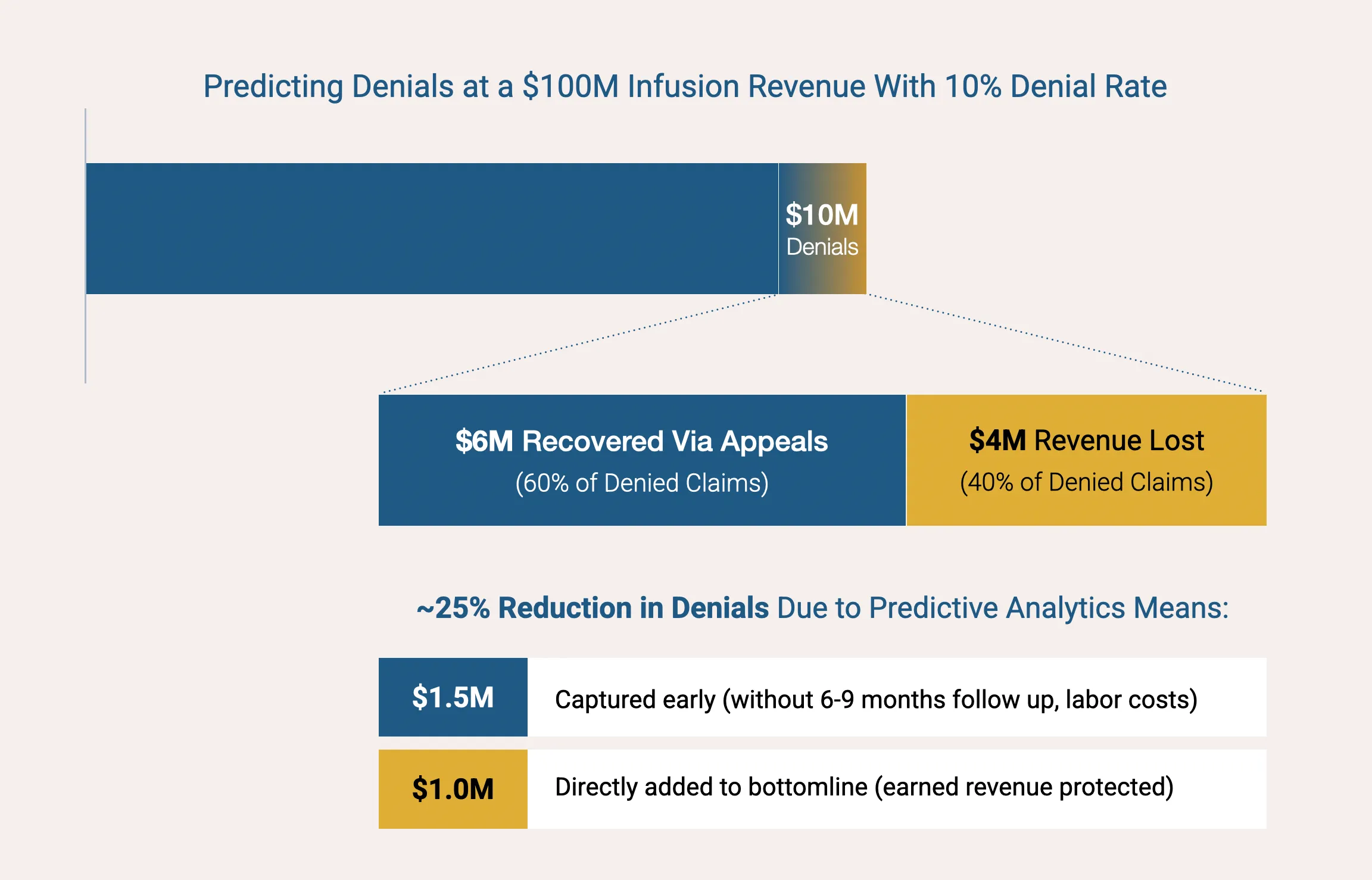
A well-built denial prediction model can reduce initial denial rates by 25%. Not by replacing your billing team, but by acting as a copilot and telling them exactly where to look before the claim leaves your building. Like all AI, the model is wrong sometimes. That's fine. The goal is directing human attention where it matters most, and the financial math on catching even a handful of high-dollar denials early is compelling.


